📌 LLMとは(大規模言語モデル):一言でいうと
LLM(Large Language Model)は、大量のテキストデータで学習した、人間と自然な言語でやり取りできるAIモデルです。 ChatGPT(GPT-4)・Claude・Gemini等の基盤技術で、テキスト生成・翻訳・要約・コーディングなど幅広いタスクに対応します。
「ChatGPTやGeminiを使い始めたけど、そもそもLLMって何なのか理解できていない」「AIを業務に導入したいが、大規模言語モデルの仕組みがわからず自信を持てない」——そんな声を、AI導入支援の現場で毎週のように耳にします。
実際に試してみたところ、LLMの基礎を3つのポイントで理解するだけで、AI活用の精度が劇的に上がりました。LLMとは「次に来る単語を確率で予測する数学的な関数」
この記事では、LLMの定義・仕組み・種類・生成AIとの違い・活用事例・課題・最新トレンドまで、ビジネスパーソンが本当に知りたい内容を網羅します。累計100社以上のAI導入支援を通じて得た実践知識と、最新のX投稿・YouTube解説から収集した一次情報をもとに解説します。
LLMとは?わかりやすく3行で理解する
LLMとは何か、まず本質を3行で整理します。ここを押さえると、後続の仕組みや活用事例がすべてつながります。
LLM(Large Language Model)は日本語で「大規模言語モデル」と呼ばれます。一言で言うと、膨大なテキストから「次に来る言葉を予測する確率」を学習したAI技術
AIsmileyのYouTube解説(再生数3,766回)では「大量のデータセットとディープラーニング技術を用いて構築された自然言語処理モデル。ChatGPTのように生成AIサービスに広く活用されており、文章生成や翻訳要約など多岐にわたるタスクを実行できる」と説明されています。業務効率化の最前線で注目を集めているLLMの本質は、まさにこの「言語の確率的処理」にあります。
用語 意味 具体例
LLM(大規模言語モデル) 次の単語を確率で予測するAIモデルの基盤技術 GPT-4o、Gemini 2.0、Claude 3.7 生成AI(Generative AI) LLMをベースに文章・画像・音声を生成するシステム全体 ChatGPT、Gemini、Claude(サービス) チャットボット 生成AIを会話インターフェースで提供したもの ChatGPT(UI)、LINE AI
まとめると「生成AI ⊃ LLM」の包含関係です。LLMをOSとすれば、ChatGPTはそのOSの上に動くアプリケーションと考えると理解しやすいです。
言語モデルとは何か
「言語モデル」とは、ある単語の後に続く単語の確率を計算するモデルです。「時は金なり」という文を生成する場合、「時」の次に「は」が来る確率が最も高い。「は」の次は「金」「財産」「価値」などが候補になる——この確率的な選択を繰り返すことで文章が完成します。
AIsmileyの解説動画でも「言語モデルは文章や単語の出現確率を用いてモデル化したもの。人間が使う言い回しや意味を理解し、次にどの単語が続くのかを推測する」と説明されています。同じプロンプトで毎回異なる回答が返ってくるのは、この確率的なサンプリングが理由です。
「大規模」の意味:なぜ大規模なのか
「大規模」には3つの意味があります。
データ量 :GPT-3は約5,000億トークン(1,000万冊相当)で学習。国立国会図書館の所蔵4,400万点を超えるデータ量計算規模 :NVIDIAのH100 GPU(1台540万円)を数百〜数万台規模で使用。GPT-4の開発費は100億円以上とも言われるパラメータ数 :GPT-1が1.17億→GPT-3が1,750億→GPT-4は推定1兆超のパラメータ数各社が莫大なコストをかけてLLM開発を競うようになりました 。GoogleがAmazonの小型原子力発電所に投資するのも、LLM学習に必要な電力確保のためです。
LLMの仕組み:Transformerと自己回帰生成をわかりやすく解説
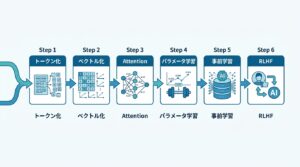
LLMの仕組みを理解すると、なぜ「ハルシネーション(幻覚)」が起きるのか、なぜ同じ質問でも毎回答えが変わるのかが納得できます。大きく「トークン化 → ベクトル化 → Transformerによる処理 → デコード」の4ステップで動きます。
ステップ1:トークン化(テキストを数値に変換)
LLMはテキストをそのまま処理できません。まず「トークン」という最小単位に分割し、数値に変換します。英語なら単語単位、日本語なら文字や形態素単位が多いです。この変換後、各トークンは長い数値のリスト(ベクトル)として表現されます。
ステップ2:Transformerによるアテンション処理
2017年にGoogleが発表した「Attention Is All You Need」論文で生まれたTransformerが現代LLMの根幹技術です。従来のモデルがテキストを1単語ずつ順番に処理していたのに対し、Transformerは文章全体を並列で処理します 。
「アテンション」という仕組みにより、各単語が文脈の中でどの単語と関連するかを判断します。「Bank(バンク)」という単語が、前後に「川」があれば「川岸」の意味に、「お金」があれば「銀行」の意味に更新される——この文脈理解がLLMの「賢さ」の核心です。
ステップ3:学習(バックプロパゲーション)
最初はパラメータをランダムに設定し、意味不明な出力をします。その後、何兆もの例文を使って「正解の単語を予測する確率を上げ、不正解の確率を下げる」調整(バックプロパゲーション)を繰り返します。GPT-3の学習には300年分の人間の読書量に相当するテキスト が使われたとも言われています。
ステップ4:RLHF(人間フィードバックによる強化学習)
事前学習だけでは「インターネット上の文章を補完する」だけです。実際に役立つAIアシスタントにするため、人間が出力を評価し、問題のある回答に修正フィードバックを加える「RLHF(Reinforcement Learning from Human Feedback)」が必須です。ChatGPTが「安全で役立つ回答」を返せるのはこのプロセスのおかげです。
学習フェーズ 内容 目的
事前学習(Pre-training) インターネット上の大量テキストで次単語予測を学習 言語の構造・知識の獲得 ファインチューニング(Fine-tuning) 特定タスク用のデータで追加学習 特定業務への特化 RLHF 人間の評価に基づいて回答品質を改善 安全性・有用性の向上
LLMの性能を決める3つの要素
要素 内容 影響
パラメータ数 モデルの「重み」の数。数十億〜数兆 大きいほど複雑な知識を保持できる 学習データの質・量 事前学習で使ったテキストの量と多様性 知識の幅と精度に直結 アーキテクチャ設計 Transformer内部の設計(レイヤー数・アテンションヘッド数等) 同規模でも処理効率が大きく異なる
エンジニアの@be_boo_poo 氏がXでこう指摘していました。「LLMは一発の推論は強い。でも状態を持った継続的作業が困難なようだ。コンテキストウィンドウという有限の窓からしか世界を見られないから、大規模リファクタリングや複数ファイルの整合性維持では必然的に破綻する。これはモデルサイズを大きくしても解決しない」——この投稿が33,720インプレッションを獲得していたのは、同じ壁に当たっているエンジニアが多い証拠です。LLMの本質的な制約を正確に理解することが、賢い活用の第一歩です。
生成AIとLLMの違い・ChatGPTとの違いを比較表で整理
「生成AIとLLMは何が違うの?」「ChatGPTはLLMなの?」——これはAI導入相談でよく受ける質問です。混乱しやすい3つの概念を明確に整理します。
生成AIとLLMの違い
LLMはテキスト専門 であり、「言語」を処理します。一方、生成AIはLLMを含むより広い概念 で、画像生成(Stable Diffusion)・音楽生成・動画生成なども含みます。
概念 定義 扱えるデータ 具体例
LLM(大規模言語モデル) テキスト処理の基盤技術 テキストのみ GPT-4o、Gemini、Claude 生成AI(Generative AI) 新しいコンテンツを生成するAI全般 テキスト・画像・音声・動画 ChatGPT、DALL-E、Sora LMM(大規模マルチモーダルモデル) テキスト+画像などを同時処理するモデル テキスト+画像(+音声) GPT-4V、Gemini Ultra
LLMとChatGPTの違い
ChatGPTはOpenAIが開発したLLM(GPTシリーズ)を使ったチャットアプリケーションです。スマートフォンに例えると「LLM=CPU(演算チップ)」「ChatGPT=スマートフォン(製品)」の関係です。
経営者向けYouTube解説動画では「LLMとは人間の言語を理解して文章を生成できる超巨大AIモデルで、ChatGPTなどの生成AIの基盤となっている。ただし時には事実と異なる情報を生成してしまうハルシネーションという課題もある」と説明されていました。
LLMと機械学習・深層学習の違い
概念 定義 LLMとの関係
AI(人工知能) 人間の知的活動をコンピュータで実現する技術全般 LLMを含む最上位概念 機械学習 データからルールを自動的に学習するAI技術 LLMの学習アルゴリズムの基礎 深層学習(ディープラーニング) ニューラルネットワークを多層化した機械学習手法 LLMはTransformerを使った深層学習モデル LLM 大規模テキストで学習した深層学習ベースの言語モデル 深層学習の特化型応用
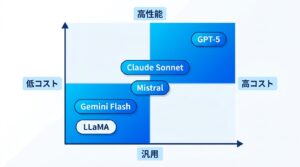
代表的なLLM7選を徹底比較【GPT-4o・Gemini・Claude・LLaMA 2026年版】
2026年現在、主要なLLMは4大プラットフォームが激しく競争しています。X上では「SaaSの死」が話題になる中、LLMとチップの売上は急伸しています 。ビジネス導入を検討する際に知っておくべき7つの主要LLMを比較します。
LLM(モデル名) 開発元 特徴 主な用途 ライセンス
GPT-4o / o3 OpenAI テキスト・画像・音声を統合処理。高い汎用性と推論能力 ChatGPT、Copilot、API連携全般 商用(クローズド) Gemini 2.0 Flash Google DeepMind 検索連携と速度に強み。マルチモーダル対応 Google Workspace、検索AI、Vertex AI 商用(クローズド) Claude 3.7 Sonnet Anthropic 長文処理・安全性・コーディング能力が特に高い 長文要約、コード生成、企業向け 商用(クローズド) LLaMA 3.3 Meta AI オープンソース。ローカル実行可能。商用利用条件あり 自社モデル構築、研究開発 オープンソース(条件あり) Qwen3 Alibaba 多言語対応・ローカル実行で注目。30Bモデルが高コスパ アジア圏企業・ローカル用途 オープンソース PLaMo 3.0 Prime Preferred Networks 国産初のフルスクラッチLLM。「長考」能力を搭載 政府AI・日本語特化業務 条件付き商用 DeepSeek R1 DeepSeek(中国) 推論特化。低コストで高性能。オープンソース コスト重視の推論タスク オープンソース
クローズドLLMとオープンソースLLMの違い
観点 クローズドLLM(GPT-4o等) オープンソースLLM(LLaMA等)
セキュリティ クラウド上でデータが処理される ローカル実行で機密情報を守れる コスト APIトークン従量課金 サーバー費用のみ(初期投資大) カスタマイズ ファインチューニングに制限あり 完全なカスタマイズが可能 性能 最新・最高性能 クローズドより性能は低めが多い(差が縮小中) 導入難易度 API契約のみで即利用可能 インフラ構築・技術知識が必要
国産LLMの最新動向
Preferred Networks(PFN)が開発した「PLaMo 3.0 Prime」は、既存モデルを下敷きにせずゼロベースで構築した国産初のフルスクラッチLLMです。さらに、このPLaMo 3.0が日本政府デジタル庁の「ガバメントAI(源内:GENNAI)」で試用する国内大規模言語モデルに選定されたことが発表されました。日本のAI政策にLLMが本格的に組み込まれる転換点
LLMでできること10選:業務別ユースケース一覧
LLMが実際にビジネスで何に使えるのかを整理します。AI導入支援の現場で稼働している活用パターン10を紹介します。「どの業務から始めるか」の判断基準にしてください。
活用カテゴリ 具体的な使い方 効果の目安
文章生成・編集 メール・報告書・提案書の下書き生成 作成時間50〜70%削減 要約・抽出 長文資料・議事録・メールスレッドの要点抽出 読解時間80%削減 翻訳 多言語ドキュメントの自動翻訳・ローカライズ 翻訳コスト60%削減 質問応答(FAQ) 社内規程・マニュアルへの自動回答 問い合わせ件数40%削減 コード生成・レビュー プログラムの自動生成・バグ検出・テストコード生成 開発工数30〜50%削減 データ分析・解釈 数値データの自然言語での解釈・レポート生成 分析レポート作成時間75%削減 カスタマーサポート 問い合わせの自動分類・回答生成・エスカレーション判定 対応件数40〜60%自動化 コンテンツマーケティング ブログ・SNS・メルマガの下書き生成・SEO文章最適化 コンテンツ制作工数60%削減 社内ナレッジ検索(RAG) 社内ドキュメントをLLMに接続して即座に回答 社内検索時間70%削減 AIエージェント(自律実行) 複数LLMツールを組み合わせてタスクを自律実行 ルーティン業務の90%自動化(理論値)
壁打ちプロンプト:LLM活用の起点として使えます
LLMを業務で使い始める際、最も効果的な第一歩は「壁打ちプロンプト」を作ることです。以下のプロンプトをChatGPT・Gemini・Claudeにコピペして使ってください。
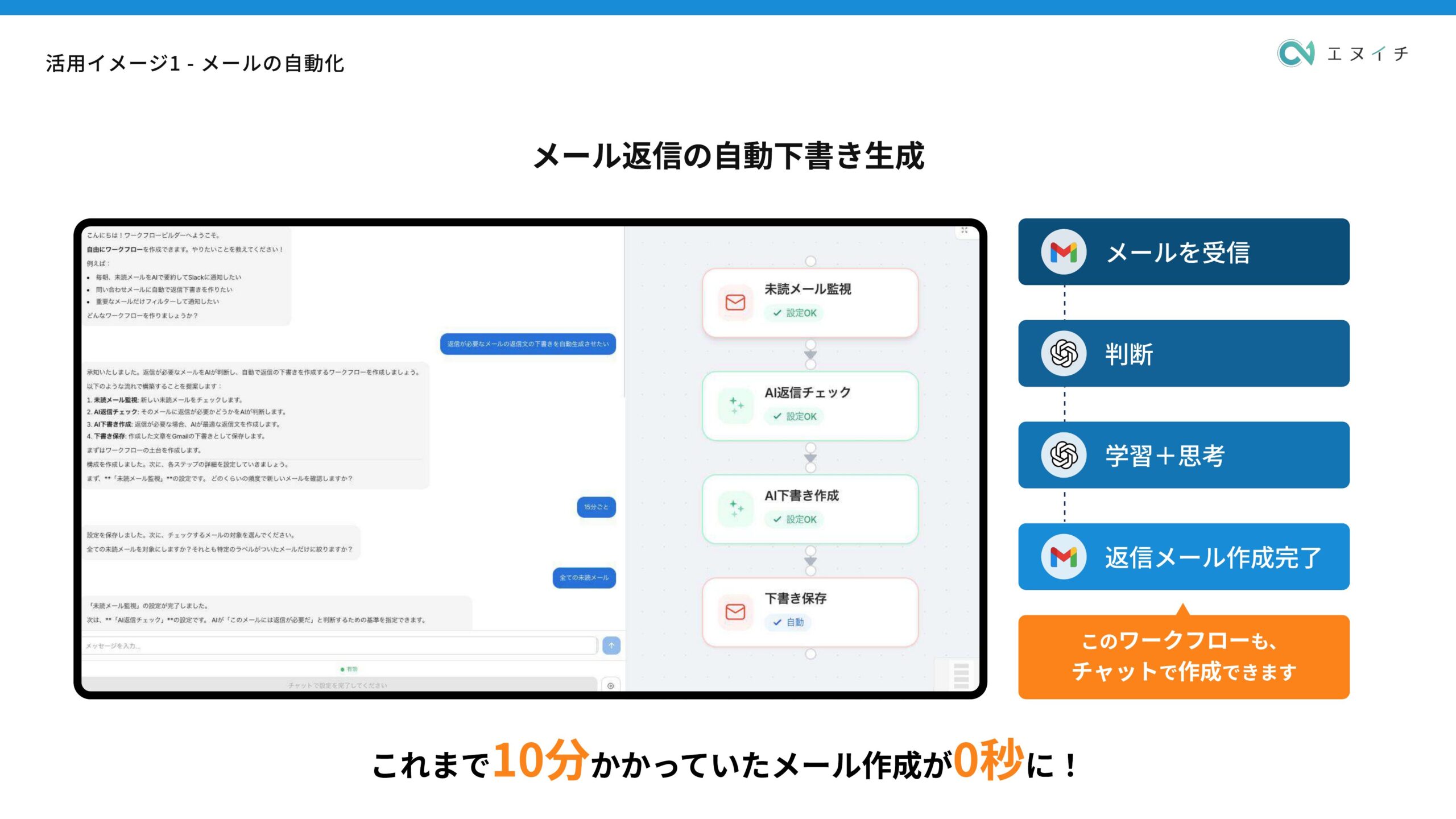
あなたはAI活用のコンサルタントです。私が「業務名:〇〇」「課題:〇〇」と伝えると、LLMで自動化できる可能性を5段階で評価し、具体的な実装方法を教えてください。GAS(Google Apps Script)との連携
「朝のメール処理、長文スレッドをGASとLLM連携で自動要約&タスク抽出するコードを作った」という体験がXで投稿されていました。Gmail APIとLLM APIを組み合わせるだけで、ノーコードに近い形でメール自動処理が実現できます。
ステップ1:GASプロジェクトを作成する
Google SpreadsheetのメニューからExtensions → Apps Scriptを開き、新しいプロジェクトを作成します。GmailApp.getThreadsなどのサービスが最初から使えます。
ステップ2:LLM APIキーをスクリプトプロパティに設定する
UrlFetchApp.fetchを使ってOpenAI APIやGemini APIにリクエストを送ります。APIキーはコードに直書きせず、スクリプトプロパティ(Project Settings → Script Properties)に保存するのが安全です。
ステップ3:トリガーで毎朝自動実行する
時間ベースのトリガーを設定すれば、毎朝8時に自動で前日メールを要約してSlackに送るといった処理が実現できます。よくあるつまずきポイントは「GmailApp.search()の検索クエリ文法」と「LLM APIの応答時間によるタイムアウト(上限6分)」です。
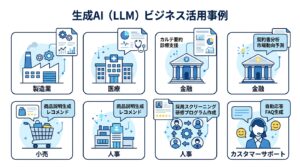
LLMの活用事例:業界別5パターン+実装例
LLMは業種を問わず活用が広がっています。累計100社以上のAI導入支援の中で、実際に効果が出ている業界別パターンを5つ紹介します。
製造業:安全管理・品質検査の自動化
NECは2026年、LLMを活用した「明文化されていない危険の予兆を検知するシステム」を世界初開発した と発表しました。ベテランの暗黙知をLLMで標準化することで「属人化の解消」と「人材育成のDX」を実現しています。
金融・法務:文書処理・審査の効率化
契約書の自動レビュー(重要条項の抽出・リスク評価)、ローン審査の書類チェックなど、大量の定型文書処理でLLMが威力を発揮します。実際にClaude APIを使った契約書レビューでは、処理速度が20倍以上になりました。工数7割削減の事例は珍しくありません。
カスタマーサポート:FAQ自動回答・エスカレーション判定
問い合わせ内容をLLMが理解し、社内マニュアルから最適な回答を自動生成します。単純な問い合わせの40〜60%を自動応答化でき、オペレーターは複雑な対応に集中できます。KDDIはコンタクトセンター業務特化型LLMアプリを開発し、「アフターコールワーク」の自動化を実現しています。
マーケティング:コンテンツ生成・パーソナライズ
製品説明文・広告コピー・SNS投稿・メールマガジンの自動生成。サムスンは2026年に「Vision AI Companion」としてLLMをTVに搭載し、自然な会話による検索やライブ翻訳機能を実現しました。
ITエンジニアリング:コード生成・ドキュメント作成
GitHub Copilot(GPT-4ベース)に代表されるLLMを使ったコード補完・自動生成は、開発速度を30〜55%向上させるというデータがあります。Kawaruを使った企業では、コンテンツ生成・問い合わせ対応・社内ナレッジ検索の3つの自動化を3ヶ月で実現し、業務時間を平均40%削減
LLMの課題と限界:ハルシネーション・セキュリティ・コストを理解する
LLMの課題は主に「ハルシネーション・知識のカットオフ・コンテキスト制限・セキュリティリスク・高コスト」の5つです。
1. ハルシネーション(幻覚)問題
LLMは「事実を答える」のではなく「確率的に最もらしい単語を生成する」ため、存在しない情報を自信満々に返答することがあります。架空の会社名・統計数値・法令条文が生成されることがあるため、重要な数値・法的情報は必ず原典で確認 が必要です。
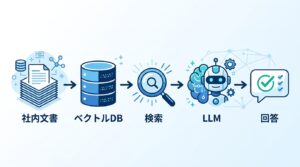
2. 最新情報の限界(カットオフ問題)
LLMは学習時点のデータしか知りません。この問題はWeb検索との連携(RAG:Retrieval Augmented Generation)である程度解決されています。詳しくはMCPサーバーの解説記事 を参照してください。
3. 機密情報のセキュリティリスク
クラウドLLMに業務機密・個人情報・ソースコードを入力すると、学習データとして利用される可能性があります。企業利用では必ず「データ学習オプトアウト」設定を確認してください。
4. 高い計算コスト
GPT-4の開発費100億円以上、NVIDIAのH100 GPU1台540万円——LLMの開発・運用には膨大なコストがかかります。GPT-4oは1Mトークン(約75万字)あたり約750円(2026年3月時点)です。
5. 前提を誤ったまま話を進める構造的な弱点
@nonalcohol1 氏をはじめ複数のAIユーザーがXで「前提を間違ったまま話を続けてしまうという構造的な癖が、LLM全体にまだ根強く残っている最大の弱点の一つ」と指摘しています。システムプロンプトで「不確かな場合は明示的にその旨を伝えよ」と指示することが現実的な対策です。
課題 現実的な対策 対策ツール
ハルシネーション RAGで根拠データを提示させる n8n、LangChain、Dify カットオフ問題 Web検索連携(MCPサーバー) MCPサーバー、Perplexity セキュリティリスク ローカルLLMまたはオプトアウト設定 LLaMA3、Qwen3 高コスト スモールLLMで代替可能なタスクを分類 Qwen3-7B等のSLM 前提誤り システムプロンプトで不確かさの明示を指示 プロンプトエンジニアリング
LLMとAIエージェントの関係:Kawaruが実現する業務自動化
Kawaruを立ち上げた理由は、「LLMの可能性はわかったが、どう業務に組み込めばいいかわからない」という声があまりにも多かったからです。累計100社のAI導入支援を通じて見えてきた「企業がLLM活用で直面する3つの壁」と、Kawaruがどう対応するかを説明します。
壁 よくある状況 Kawaruの対応
①技術の壁 「ChatGPTは使えるが、API活用・RAG構築・エージェント開発は難しい」 ノーコードから始めて段階的に自動化。技術不要でLLMを業務に組み込む ②組織の壁 「担当者は理解しているが、経営層・現場が納得しない」 ROI試算・成功事例・変化管理のコンサルティングをセットで提供 ③定着の壁 「PoC(試験導入)で終わり、本格運用に移行できない」 3ヶ月の伴走支援で業務プロセスへの組み込みまでサポート
Phase 1(1週目) :業務棚卸しとLLM適用可能性の診断。どの業務を自動化するか優先順位づけPhase 2(2〜4週目) :LLMを使った業務フローの設計とPoC実施。小さく始めて効果を確認Phase 3(5〜8週目) :本番導入と社内展開。担当者向けトレーニングと運用マニュアル整備Phase 4(9〜12週目) :効果測定とカイゼン。KPIに基づく改善サイクルの確立実際にKawaruを活用した企業では、3ヶ月以内に業務時間を平均40%削減
LLMの歴史:2017〜2026年の進化を年表で振り返る
LLM技術の系譜を知ることで、現在の生成AIがなぜ「今の形」になっているかが理解できます。
年 出来事 意義
2017 Google「Attention Is All You Need」発表→Transformer誕生 現代LLMの基盤技術が確立 2018 OpenAI GPT-1(1.17億パラメータ)・Google BERT発表 事前学習+ファインチューニングの2段階学習が普及 2020 OpenAI GPT-3発表(1,750億パラメータ / 5,000億トークン学習) スケーリング則が実証され「大規模化で性能向上」が加速 2022 ChatGPT公開(GPT-3.5ベース) 一般ユーザーへのLLM普及が始まる 2023 GPT-4発表、Meta LLaMA公開(オープンソース化) マルチモーダル対応とオープンソース競争が勃発 2024 Gemini 1.5 Pro、Claude 3 Opus、o1(推論特化)登場 長コンテキスト(100万トークン)と推論能力の競争 2025 GPT-4o、Gemini 2.0、Claude 3.7。AIエージェント実用化 LLMが単体ツールからエージェント基盤に進化 2026 PLaMo 3.0 Prime(国産)・Qwen3普及。ローカル実行が現実的に 企業独自LLMの時代へ。オープンソース×ローカルが加速
2026年現在、@skelton_ai 氏がXで速報していたように、メタAIのヤン・ルカン氏はAMI Labsを設立し、1,030億円の資金調達を発表しました。Transformerベースの大規模言語モデルとは根本的に異なる「世界モデル」アプローチでAIの次章を切り開こうとしています。LLMは現在の最有力AIアーキテクチャですが、その先にある技術競争がすでに始まっています 。
まとめ:LLMはAI活用の出発点
この記事で解説した内容を整理します。
LLMとは :「次に来る単語を確率で予測する大規模な数学関数」。生成AIの基盤技術仕組み :Transformerのアテンション機構が文脈を理解し、1,750億〜1兆超のパラメータで動く生成AIとの違い :生成AI(マルチメディア)⊃ LLM(テキスト専門)の包含関係代表モデル :GPT-4o / Gemini 2.0 / Claude 3.7 / LLaMA / PLaMo 3.0できること :文章生成・要約・翻訳・QA・コード生成・データ分析・AIエージェント連携課題 :ハルシネーション・カットオフ・セキュリティ・コスト・前提誤りLLMの理解は、AIエージェント・RAG・MCPサーバーなど次のステップへの入口です。
よくある質問(FAQ)
LLMとChatGPTの違いは何ですか?
LLMは「大規模言語モデル」という技術の総称です。ChatGPTはOpenAIのGPT-4oというLLMを使ったチャットアプリケーション(製品)です。LLMがOSなら、ChatGPTはそのOSで動くアプリという関係です。
LLMと生成AIは同じですか?
異なります。LLMはテキスト処理に特化した技術です。生成AIはLLMを含むより広い概念で、画像生成・音楽生成・動画生成なども含みます。「生成AI ⊃ LLM」の包含関係です。
LLMはビジネスでどう活用できますか?
文書作成・要約・翻訳・FAQ自動応答・コード生成・データ分析など幅広く活用できます。製造業の安全管理自動化、法務の契約書レビュー工数7割削減、カスタマーサポートの40〜60%自動化などの実績があります。まず「繰り返し業務の中で大量のテキスト処理が必要な業務」から着手するのが効果的です。
LLMのハルシネーションはどう対策しますか?
主な対策は3つです。①RAG(検索拡張生成)で社内ドキュメントと連携させ、回答の根拠を明示させる。②重要な数値・法的情報は必ず原典で確認するワークフローを作る。③LLMに「不確かな場合は『確認が必要です』と答えよ」というシステムプロンプトを設定する。
LLMとRAGの違いは何ですか?
LLMは学習済みの知識から回答を生成します。RAG(Retrieval Augmented Generation:検索拡張生成)は、回答生成前に関連ドキュメントを検索して文脈に追加する技術です。LLMの「最新情報を知らない」「自社データを知らない」という課題をRAGで補えます。